Experience

Stud
Stud
The Irish National Stud provides breeders an opportunity to access top class stallions and services including boarding, sales preparations and foaling.
LEARN MORE
Irish Racehorse Experience
Irish Racehorse Experience
Visit the Irish Racehorse Experience and learn the lifecycle of the Irish thoroughbred. A unique immersive experience, create their story and guide them to glory.
LEARN MORE
Gardens
Gardens
The Irish National Stud’s Japanese Gardens, renowned throughout the world and the finest of their kind in Europe.
LEARN MORE

Kids Zone
Kids Zone
The Irish National Stud & Gardens offers a fun-filled day for the whole family.
LEARN MOREStallions
- Phoenix of Spain
- Nando Parrado
- Mac Swiney
- Lucky Vega
- Invincible Spirit
- Equiano
- Elusive Pimpernel







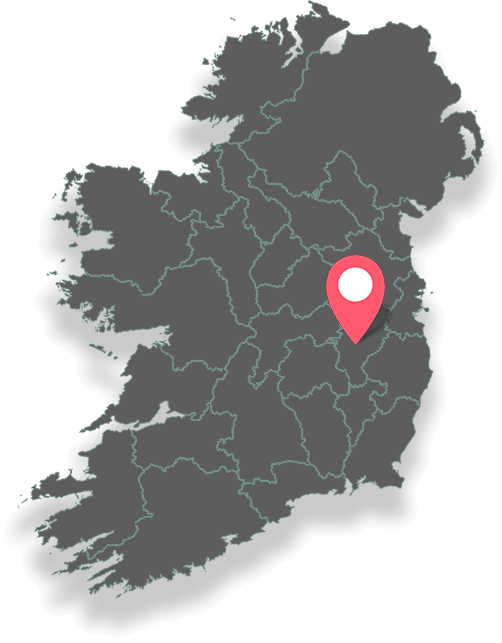
Directions
Brallistown Little, Tully, Co. Kildare, R51 KX25, Ireland
Location
The Irish National Stud in Co. Kildare is an ideal family trip from a number of locations in Ireland with it being only 45 minutes from Dublin and two hours from Waterford, Cork and Galway.
By Car
Travelling from the M7 take Exit 13 in the direction of Nurney on the R415 as far as Newtown Cross. Turn left and continue to the T-Junction. Signage will bring you to the grounds.
By Train
There is a Direct Rail Service to Kildare from Dublin, Limerick, Waterford, Westport and Cork (via Portlaoise). Visit www.irishrail.ie to view timetables.
Our Blogs READ ALL

































































































































































What Visitors thinkVIEW ALL
Local Guide


Hayclay
Really enjoyed our trip to the National Stud (wish we had something similar in England!). Luke was an excellent and knowledgable tour guide.
Highlight was meeting the retired legends (especially Faugheen!) and being able to wander about and see the size of the stud. Obviously not many horses about because of the time of year but still excellent.
The Japanese garden was quite small but like a maze so felt much bigger.
Definitely recommend a trip if you’re that way, and very reasonably priced!
Local Guide

Laura Jane Johanna
A fabulous layout, the gardens are intricate and interesting. There are lots of fun surprises in the layout of the Japanese gardens too, we had small children with us and they were safe and able for all the steps and climbs. I would say some of it isn’t suitable for prams or wheelchairs but a lot of the grounds are. The plant diversity was wonderful. The food in the cafe on the grounds is more dinner food, it is quite expensive but the portions are big and the food is well worth it. The staff are polite and the cafe and grounds are very clean.
Local Guide

Mario Braz
The place is amazing.
Relaxing place to be with plenty benches around.
Beautiful Japanese Garden
Unfortunately some people don’t respect this place by throwing trash on the grass and leaving paper cups around.
Local Guide

April M
Beautiful grounds to walk and the cafe on site has lovely food too. Great for a nice day out, very tranquil and relaxing place to be. Plenty of benches to sit down and enjoy the wildlife and scenery. Really great spot, ample parking too
Local Guide

Tetiana Magai
It’s very lovely place. Very beautiful nature 🌳Imazing horses 🐎 there are also playgrounds for children. Also wonderful The Chinese garden🌺🌻🌹🌷
Local Guide

Phil Brennan
Great family day out. Despite being very busy, full car park and overflow, it never felt crowded. Lots to do and see, great value for a family of 5. We’ll be back.
Local Guide


Caroline Kirwan
Have seen Halloween event for free if you buy day entry. Avail it but wasn’t able to come on time 11am-3pm for the Halloween event. But the place itself was very nice for a family day out. They have horses out , fairy trail , big long walks , Japanese gardens , playgrounds and cafe when you come in the end of your walk and have a cafe near the playground too. Highly recommended to wear rain boats for the kids on our weather lately. They have guided tours too . I think they have more just didn’t suited our kids age. Check out website for more information about the tours . 😊
Local Guide

mick moylan
Well I think it was a good idea to go here early on a Monday as it beat the late risers and some school tours..it’s 14 euro entrance fee and 11 euro if you’re an old ager..I took a guided tour around the Stud Farm which was very enlightening..and then had lunch in the restaurant..food was very nice and tasty and reasonably priced and staff were very helpful ..I finished off with a walk around the Japanese gardens which is always relaxing
Local Guide

Ian Ross
Gardens are amazing, nice afternoon spent wandering about, taking pictures and having a picnic, the Japanese Gardens were especially good. Beautiful flowers and trees and the intricate walkways were lots of fun for adults and kids alike. National stud was interesting too. Great day out for all the family.
Local Guide

Gary Shekleton
Stunning horse stud & gardens
Easy to get from the M7 (exit 13) and great parking availability which is free / not chargeable.
The grounds & Gardens are so well kept and it’s very scenic.
Extremely nice place to go for a walk and to appreciate the horses on site, but also the amazing gardens including the Japanese styled gardens.
They also have a cafe/restaurant here and they also offer tours at different times.
Definitely would recommend to see this amazing estate. 👍
HAVE A QUESTION?
Drop a Line
Address
Irish National Stud & Gardens,
Brallistown Little, Tully, Co. Kildare,
R51 KX25, Ireland